
.NET Core的DDD架构
DDD的基本概念
什么是微服务
单体结构
传统的软件项目大部分都是单体结构,也就是项目中的所有代码都放到同一个应用程序中,一般他们也都运行在同一个进程中。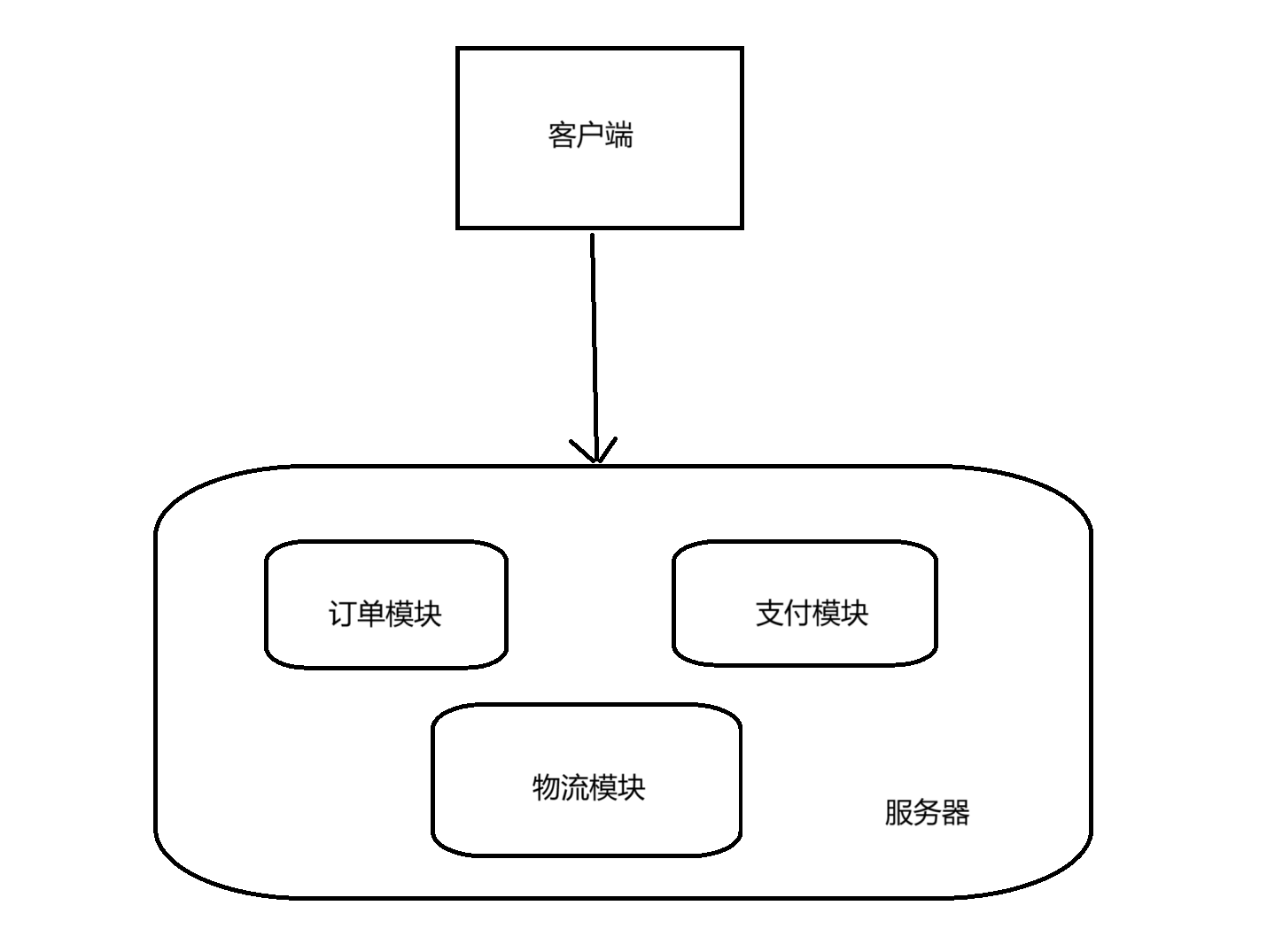
单体结构的项目有结构简单、部署简单等优点,但是有如下缺点:
- 代码之间耦合严重,代码的可维护性低。
- 项目只能采用单一的语言和技术栈,甚至采用的开发包的版本都必须统一。
- 一个模块的崩溃就会导致整个项目的崩溃。
- 我们只能整体进行服务器扩容,无法对其中一个模块进行单独的服务器扩容。
- 当需要更新某一个功能时,我们需要把整个系统重新部署一遍,这会导致新功能的上线流程变长。
微服务架构
微服务架构把项目拆分为多个应用程序,每个程序单独构建和部署。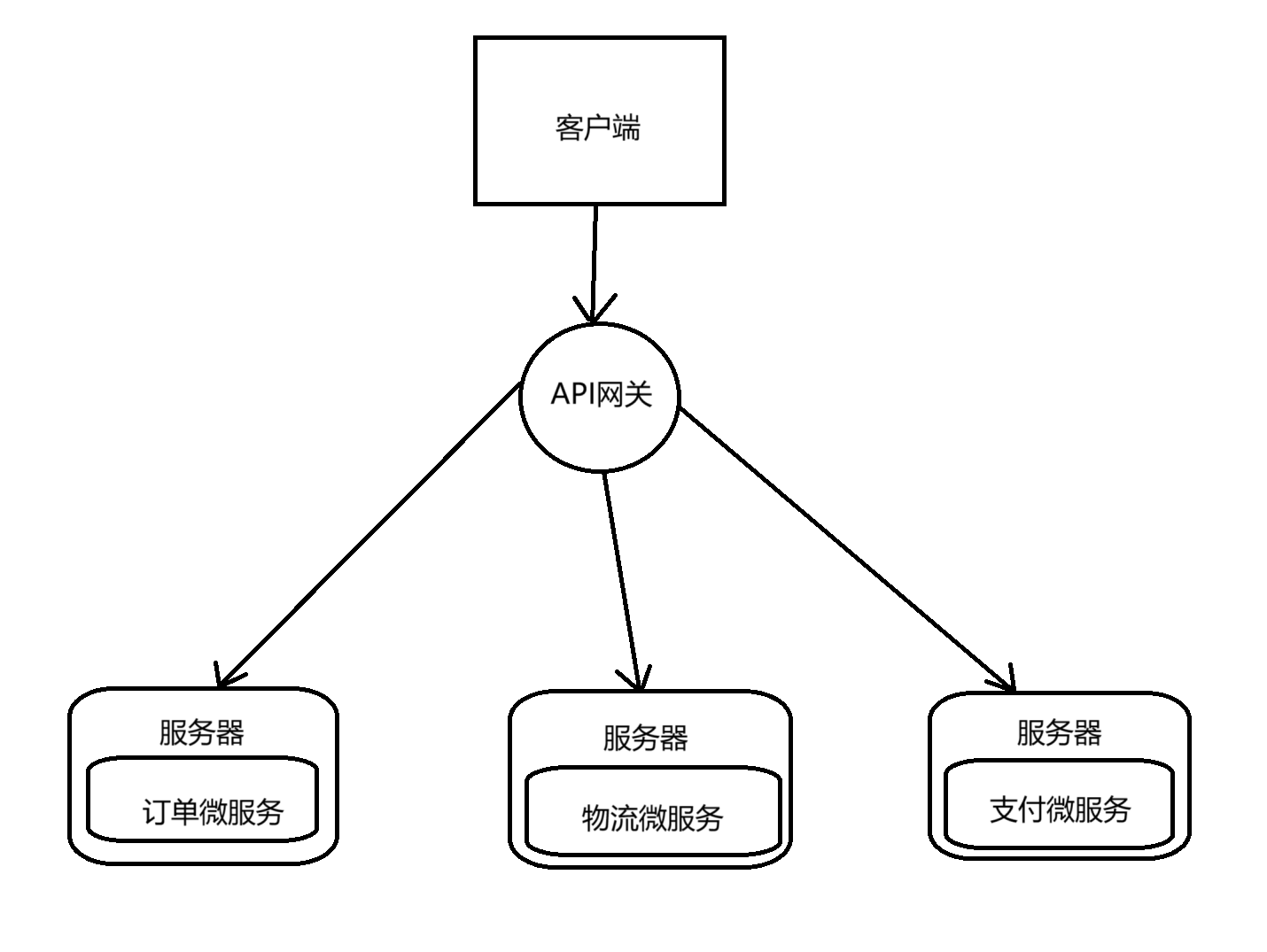
微服务架构有如下的优点:
- 每个微服务只负责一个特定的业务,业务逻辑清晰、代码简单,对于其他微服务的依赖非常低,因此易于开发和维护。
- 不同的微服务可以用不同的语言和技术栈开发。
- 一个微服务的运行不会影响其他微服务。
- 可以对一个特定的微服务进行单独维护可容。
- 当需要更新某个功能的时候,我们只需要重新部署这个功能所在的微服务即可,不需要重新部署整个系统。
微服务架构缺点:
- 在单体结构中,运维人员只需要保证一个应用的正常运行即可,而在微服务架构中,运维人员需要保证多应用的正常运行,这给运维人员带来更大的挑战。
- 在单体结构中,各模块之间是进程内调用,数据交互的效率高,而在微服务架构中,和微服务之间要通过网络进行通信,数据交互的效率低。
- 在单体结构中,各模块之间的调用都是在进程内进行的,实现容错、事务一致性等比较容易,而在微服务架构中,各微服务之间通过网络通信,实现容错、实物一致性等非常困难。
DDD之领域模型
- 领域(Domain):一个组织做的事情。子领域。
- 领域的划分(以手机公司为例):
核心域:解决项目的核心问题,和组织业务紧密相关。
支撑域:解决项目的非核心问题,则具有组织特性,但不具有通用性。
通用域:解决通用问题,没有组织特性。 - 领域的不同分类决定了公司的研发重点。
领域模型(Domain Model)
- 对于领域内的对象进行建模,从而抽象出来模型。
- 我们的项目应该开始于创建领域模型,而不是考虑如何设计数据库和编写代码。适用领域模型,我们可以一直用业务语言去描述和构建系统,而不是使用技术人员的语言。
实体类与值对象
实体类
- “标识符”用来唯一定位一个对象,在数据库中我们一般用表的主键来实现“标识符”。主键和标识符的思考角度不同。
- “实体”拥有唯一的标识符,标识符的值不会改变,而对象的其他状态则会经历各种变化。标志符用来跟踪对象状态变化,一个实体的对象无论怎样变化,我们都能通过标识符定位这个对象。
- 是他一般的表现形式就是EF Core中的实体类。
值对象
- 值对象:没有标志符的对象,也有多个属性,依附于某个实体类对象而存在。比如“商家”的地理位置、衣服的RGB颜色。
- 定义为值对象和普通属性的区别:体现整体关系。
聚合和聚合根
- 聚合(Aggregate)
定义:聚合是由多个关联对象组合而成的一个整体,这些对象在业务逻辑上相互依赖,形成一个边界清晰的单元。
核心特性:
一致性边界:在进行数据修改操作时,聚合要保证内部对象状态的一致性。
作为一个整体进行引用:外部对象只能引用聚合根,而不能直接引用聚合内部的其他成员。
生命周期管理:聚合内部对象的生命周期由聚合根统一管理。
应用场景:当处理具有复杂业务规则的实体关系时,比如订单与订单项、账户与交易记录等场景,就可以使用聚合。
- 聚合根(Aggregate Root)
定义:聚合根是聚合中的核心实体,它是外部访问聚合的唯一入口点。
核心职责:
封装内部逻辑:聚合根负责维护聚合内部对象之间的业务规则。
保证数据一致性:在聚合内部状态发生变化时,聚合根要确保这种变化符合业务规则。
管理生命周期:聚合根负责创建、删除聚合内部的对象。
应用场景:聚合根在领域服务中经常被用作事务边界,像订单管理、库存控制等场景都会用到。
3. 二者的关系
聚合根是聚合的 “代言人”,外部对象只能通过聚合根来与聚合进行交互,不能直接访问聚合内部的其他对象。
聚合根要确保聚合内部的数据在任何时候都满足业务规则,以此来维护数据的一致性。
- 设计原则
最小引用原则:要尽量减少聚合之间的关联,避免出现复杂的引用网络。
事务边界原则:一个聚合在一次事务中只能被一个聚合根修改。
不变性原则:聚合根要保证聚合内部的业务规则始终得到遵守。
DDD领域服务和应用服务
聚合根的实体类中没有业务逻辑代码,只有对象的创建、对象的初始化、状态管理等与个体相关的代码。对于聚合内的业务代码,我们编写领域服务(domain service),而对于跨聚合协作的逻辑,我们编写应用服务(application service)。应用服务协调多个领域服务来完成一个用例。
在DDD中,一个典型的用例的处理流程如下:
- 准备业务操作所需要的数据,一般是从数据库或者其他外部数据源获取数据。
- 执行由一个或多个领域模型做出的业务操作,这些操作会修改实体类的状态,或者生成一些操作结果。
- 把对实体类的改变或者操作结果应用与外部系统,比如保存对实体类的修改到数据库或者把计算结果通过短信发送给用户。
上面的步骤中,只有第一步和第三步涉及与外部系统的交互,第二步是对领域模型的业务逻辑操作。这三步组成一个典型的应用服务的逻辑,而若个领域服务被编排完成第二步的工作。领域模型与外部系统(数据库、缓存等)是隔离的,不会发生直接交互,也就是说领域服务不会涉及读写数据库的操纵。这样我们可以很好地实现责任的划分:业务逻辑放入领域服务,而与外部系统的交互由应用服务来负责。因为领域服务是用来协调领域对象完成业务逻辑操作的,所以领域服务是无状态的,状态由领域对象来管理。
需要注意的是,领域服务不是必需的,在一些简单的业务处理(比如增、删、改、查)中是没有领域知识(也就是业务逻辑)的,这种情况下应用服务可以完成所有操作,不需要引入领域服务,这样我们可以避免系统出现过度设计的问题。如果随着系统的进化,应用服务中出现了业务逻辑,我们就要把业务逻辑放入领域服务。
和聚合相关的两个概念是“仓储”(repository)和“工作单元”(unit of work)。聚合中的实体类不负责数据库读取和保存,这些工作是有仓库储负责的因此实体类负责业务逻辑的处理,仓储负责按照要求从数据库中读取数据已及把领域服务修改的数据保存回数据库,一个聚合对应一个用来实现数据持久化的仓储。聚合内数据操作的关系是非常紧密的,我们要保证事务的强一致性,而聚合间的协作是关系不紧密的,因此我们只要保证事务的最终一致性即可。聚合内的若干相关联的操作组成一个“工作单元”,这些工作单元要么全部成功,要么全部失败。
因为领域服务不依赖外部系统、不保存状态,所以领域服务比应用服务更容易进行单元测试,这对于提高系统的质量是非常有帮助的。

